DrWatson Workflow Tutorial
Disclaimer: DrWatson assumes basic knowledge of how Julia's project manager works.
This example page demonstrates how DrWatson's functions help a typical scientific workflow, as illustrated below:
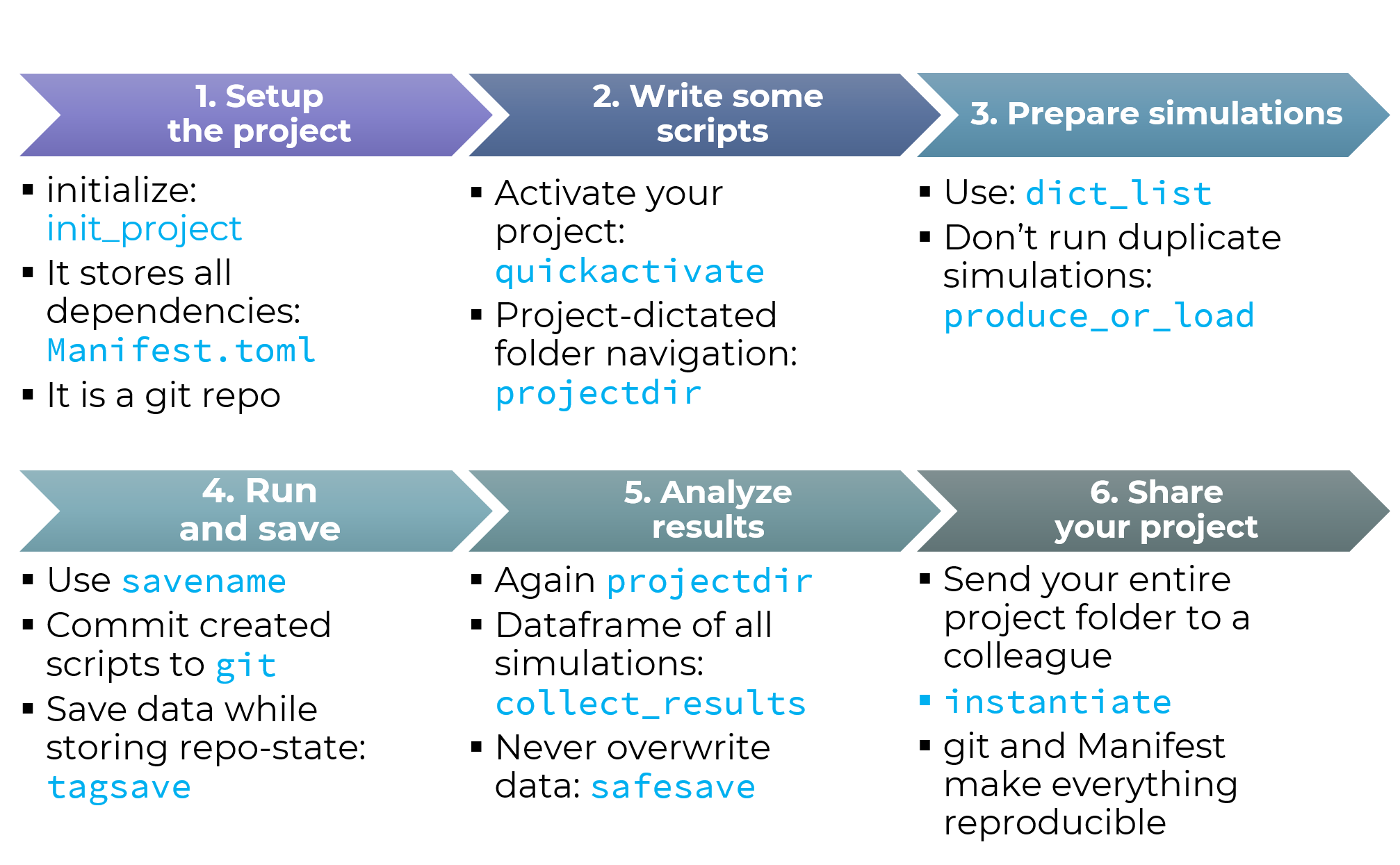
Blue text comes from DrWatson. Of course, not all of DrWatson's functionality will be highlighted in this tutorial nor is shown in the above figure!
1. Setup the project
So, let's start a new scientific project. You want your project to be contained in a folder. So let's create a new project, located at current working directory
using DrWatson
# prefer project names without spaces!
initialize_project("DrWatsonExample"; authors="Datseris", force=true)"DrWatsonExample"Alright now we have a project set up. The project has a default reasonable structure, as illustrated in the Default Project Setup page:
│projectdir <- Project's main folder. It is initialized as a Git
│ repository with a reasonable .gitignore file.
│
├── _research <- WIP scripts, code, notes, comments,
│ | to-dos and anything in an alpha state.
│ └── tmp <- Temporary data folder.
│
├── data <- **Immutable and add-only!**
│ ├── sims <- Data resulting directly from simulations.
│ ├── exp_pro <- Data from processing experiments.
│ └── exp_raw <- Raw experimental data.
│
├── plots <- Self-explanatory.
├── notebooks <- Jupyter, Weave or any other mixed media notebooks.
│
├── papers <- Scientific papers resulting from the project.
│
├── scripts <- Various scripts, e.g. simulations, plotting, analysis,
│ │ The scripts use the `src` folder for their base code.
│ └── intro.jl <- Simple file that uses DrWatson and uses its greeting.
│
├── src <- Source code for use in this project. Contains functions,
│ structures and modules that are used throughout
│ the project and in multiple scripts.
│
├── test <- Folder containing tests for `src`.
│ └── runtests.jl <- Main test file, also run via continuous integration.
│
├── README.md <- Optional top-level README for anyone using this project.
├── .gitignore <- by default ignores _research, data, plots, videos,
│ notebooks and latex-compilation related files.
│
├── Manifest.toml <- Contains full list of exact package versions used currently.
└── Project.toml <- Main project file, allows activation and installation.
Includes DrWatson by default.
For example, folders exist for data, plots, scripts, source code, etc. Three files are noteworthy:
- Project.toml: Defines project
- Manifest.toml: Contains exact list of project dependencies
- .git (hidden folder): Contains reversible and searchable history of the project
The scientific project we have created is also a Julia project environment. This means that it has its own dedicated dependencies and versions of dependencies. This project is now active by default so we can start adding packages that we will be using in the project. We'll add the following for demonstrating
using Pkg
Pkg.add(["Statistics", "JLD2"]) Cloning git-repo `https://github.com/JuliaDynamics/DrWatson.jl.git`
Resolving package versions...
Updating `~/work/DrWatson.jl/DrWatson.jl/docs/build/DrWatsonExample/Project.toml`
[634d3b9d] ~ DrWatson v2.19.1 ⇒ v2.19.1 `~/.julia/dev/DrWatson`
Updating `~/work/DrWatson.jl/DrWatson.jl/docs/build/DrWatsonExample/Manifest.toml`
[634d3b9d] ~ DrWatson v2.19.1 ⇒ v2.19.1 `~/.julia/dev/DrWatson`
Resolving package versions...
Updating `~/work/DrWatson.jl/DrWatson.jl/docs/build/DrWatsonExample/Project.toml`
[033835bb] + JLD2 v0.6.2
[10745b16] + Statistics v1.11.1
Updating `~/work/DrWatson.jl/DrWatson.jl/docs/build/DrWatsonExample/Manifest.toml`
[10745b16] + Statistics v1.11.1
[37e2e46d] + LinearAlgebra v1.11.0
[e66e0078] + CompilerSupportLibraries_jll v1.1.1+0
[4536629a] + OpenBLAS_jll v0.3.27+1
[8e850b90] + libblastrampoline_jll v5.11.0+0
Precompiling project...
1778.8 ms ✓ DrWatson
1 dependency successfully precompiled in 2 seconds. 43 already precompiled.
1 dependency precompiled but a different version is currently loaded. Restart julia to access the new version. Otherwise, loading dependents of this package may trigger further precompilation to work with the unexpected version.2. Write some scripts
We start by writing some script for our project that will do some dummy calculations. Let's create scripts/example.jl in our project. All following code is supposed to exist in that file.
Now, with DrWatson every script (typically) starts with the following two lines:
using DrWatson
@quickactivate "DrWatsonExample" # <- project nameThis command does something simple: it searches the folder of the script, and its parent folders, until it finds a Project.toml. It activates that project, but if the project name doesn't match the given name (here "DrWatsonExample") it throws an error. Let's see the project we activated:
projectname()"DrWatsonExample"This is extremely useful for two reasons. First, it is guaranteed that our scripts run within the context of the project and thus use the correct package versions.
Second, DrWatson provides the powerful function projectdir and its derivatives like datadir, plotsdir, srcdir, etc.
projectdir()"/home/runner/work/DrWatson.jl/DrWatson.jl/docs/build/DrWatsonExample"projectdir will always return the path to the currently active project. It doesn't matter where its called from, or where the active project actually is. So, by using DrWatson, you don't care anymore where your current script is, you only care about the target directory.
datadir()"/home/runner/work/DrWatson.jl/DrWatson.jl/docs/build/DrWatsonExample/data"datadir("sims", "electron_gas")"/home/runner/work/DrWatson.jl/DrWatson.jl/docs/build/DrWatsonExample/data/sims/electron_gas"Giving arguments to projectdir and derivatives joins paths.
3. Prepare simulations
Let's say we write a simple simulation function, that creates some data
function fakesim(a, b, v, method = "linear")
if method == "linear"
r = @. a + b * v
elseif method == "cubic"
r = @. a*b*v^3
end
y = sqrt(b)
return r, y
endfakesim (generic function with 2 methods)and we create some parameters in our scripts and run the simulation
a, b = 2, 3
v = rand(5)
method = "linear"
r, y = fakesim(a, b, v, method)([4.916150065547004, 3.414892222252994, 2.228026580826999, 3.2231454650339626, 2.843285149405624], 1.7320508075688772)Okay, that is fine, but it is typically the case that in scientific context some simulations are done for several different combinations of parameters. It is convenient to group all parameters in a dictionary, with the keys being the parameters. Depending on the package you will use to actually save the data, the key type should be either String or Symbol. Here we will be using JLD2.jl and therefore the key type will be String.
params = @strdict a b v methodDict{String, Any} with 4 entries:
"v" => [0.97205, 0.471631, 0.0760089, 0.407715, 0.281095]
"method" => "linear"
"b" => 3
"a" => 2Above we used the ultra-cool @strdict macro, which creates a dictionary from existing variables!
Now, for every simulation we want to do, we would create such a container. We can use the dict_list to ease up the process of preparing several of these parameter containers
allparams = Dict(
"a" => [1, 2], # it is inside vector. It is expanded.
"b" => [3, 4], # same
"v" => [rand(1:2, 2)], # single element inside vector; no expansion
"method" => "linear", # not in vector = not expanded, even if naturally iterable
)
dicts = dict_list(allparams)4-element Vector{Dict{String, Any}}:
Dict("v" => [1, 1], "method" => "linear", "b" => 3, "a" => 1)
Dict("v" => [1, 1], "method" => "linear", "b" => 4, "a" => 1)
Dict("v" => [1, 1], "method" => "linear", "b" => 3, "a" => 2)
Dict("v" => [1, 1], "method" => "linear", "b" => 4, "a" => 2)using dict_list is great, because it has a very clear design on how to expand containers, while not caring whether the parameter values are iterable or not. In short everything in a Vector is expanded once (Vectors of length 1 are not expanded naturally). See dict_list for more details.
The resulting dictionaries are then typically given into a main or makesim function that actually does the simulation given some input parameters.
4. Run and save
Alright, we now have to actually save the results, so we first define:
function makesim(d::Dict)
@unpack a, b, v, method = d
r, y = fakesim(a, b, v, method)
fulld = copy(d)
fulld["r"] = r
fulld["y"] = y
return fulld
endmakesim (generic function with 1 method)and then we can save the results by once again leveraging projectdir
for (i, d) in enumerate(dicts)
f = makesim(d)
wsave(datadir("simulations", "sim_$(i).jld2"), f)
end(wsave is a function from DrWatson, that ensures that the directory you try to save the data exists. It then calls FileIO.save)
Here each simulation was named according to a somewhat arbitrary integer. Surely we can do better though! We typically want the input parameters to be part of the file name, if the parameters are few and simple, like here. E.g. here we would want the file name to be something like a=2_b=3_method=linear.jld2. It would be also nice that such a naming scheme would apply to arbitrary input parameters so that we don't have to manually write a=$(a)_b=$(b)_method=$(method) and change this code every time we change a parameter name...
Enter savename:
savename(params)"a=2_b=3_method=linear"savename takes as an input pretty much any Julia composite container with key-value pairs and transforms it into such a name. We can even do
savename(dicts[1], "jld2")"a=1_b=3_method=linear.jld2"savename is flexible and smart. As you noticed, even though the vector v with 5 numbers is part of the input, it wasn't included in the name (on purpose). See the savename documentation for more.
We now transform our make+save loop into
for (i, d) in enumerate(dicts)
f = makesim(d)
wsave(datadir("simulations", savename(d, "jld2")), f)
end
readdir(datadir("simulations"))4-element Vector{String}:
"a=1_b=3_method=linear.jld2"
"a=1_b=4_method=linear.jld2"
"a=2_b=3_method=linear.jld2"
"a=2_b=4_method=linear.jld2"That is cool, but we can do better. In fact, much better. Remember that the project initialized by DrWatson is a git repository. So, now we quickly go into git and commit the script we have created and all changes (not shown here).
Then we make+save again, but now instead of wsave we use @tagsave:
for (i, d) in enumerate(dicts)
f = makesim(d)
@tagsave(datadir("simulations", savename(d, "jld2")), f)
endand let's load the first simulation
firstsim = readdir(datadir("simulations"))[1]
wload(datadir("simulations", firstsim))Dict{String, Any} with 8 entries:
"v" => [1, 1]
"method" => "linear"
"gitcommit" => "b7c0cbe2601c969897dd36f54743d5cec080a8a6-dirty"
"script" => "docs/build/string#3"
"b" => 3
"r" => [4, 4]
"a" => 1
"y" => 1.73205So what happened is that tagsave automatically added git-related information into the file we saved (the field :gitcommit), enabling reproducibility!
It gets even better! Because @tagsave is a macro, it deduced automatically where the script that called @tagsave was located. It even includes the exact line of code that called the @tagsave command. This information is in the :script field of the saved data!
Lastly, have a look at produce_or_load to establish a workflow that helps you run data-producing simulations only once, saving you both headaches but also precious electricity!
5. Analyze results
Cool, now we can start analyzing some simulations. The actual analysis is your job, but DrWatson can help you get started with the collect_results function. Notice that you need to be using DataFrames to access the function!
Pkg.add(["DataFrames"])
using DataFrames
df = collect_results(datadir("simulations"))| Row | v | method | b | r | a | y | path |
|---|---|---|---|---|---|---|---|
| Array…? | String? | Int64? | Array…? | Int64? | Float64? | String? | |
| 1 | [1, 1] | linear | 3 | [4, 4] | 1 | 1.73205 | /home/runner/work/DrWatson.jl/DrWatson.jl/docs/build/DrWatsonExample/data/simulations/a=1_b=3_method=linear.jld2 |
| 2 | [1, 1] | linear | 4 | [5, 5] | 1 | 2.0 | /home/runner/work/DrWatson.jl/DrWatson.jl/docs/build/DrWatsonExample/data/simulations/a=1_b=4_method=linear.jld2 |
| 3 | [1, 1] | linear | 3 | [5, 5] | 2 | 1.73205 | /home/runner/work/DrWatson.jl/DrWatson.jl/docs/build/DrWatsonExample/data/simulations/a=2_b=3_method=linear.jld2 |
| 4 | [1, 1] | linear | 4 | [6, 6] | 2 | 2.0 | /home/runner/work/DrWatson.jl/DrWatson.jl/docs/build/DrWatsonExample/data/simulations/a=2_b=4_method=linear.jld2 |
Some things to note:
- the returned object is a
DataFramefor further analysis. - the input to
collect_resultis a folder, not a dataframe! The function does the loading and combining for you. - If you create new simulations, you can iteratively (or all from scratch) add them to this dataframe.
- If you create new simulations that have new parameters, that don't exist in the simulations already saved, that's no problem.
collect_resultswill appropriately and automatically addmissingto all parameter values that don't exist in previous and/or current simulations. This is demonstrated explicitly in the Adapting to new data/parameters real world example, so it is not repeated here. - Similarly with e.g.
savename,collect_resultsis a flexible function. It has several configuration options.
Great! so now we are doing some analysis and we want to save some results... It is very often the case in science that the same analysis may be done again, and again, and some times even with the same parameters... And poor scientitists sometimes forget to change the name of the output file, and end up overwritting previous work! Devastating!
To avoid such scenarios, we can use the function safesave, e.g.
analysis = 42
safesave(datadir("ana", "linear.jld2"), @strdict analysis)If a file linear.jld2 exists in that folder, it is not overwritten. Instead, it is renamed to linear#1.jld2, and a new linear.jld2 file is made!
6. Share your project
This is already discussed in the Reproducibility section of the docs so there is no reason to copy/paste everything here. What is demonstrated there is that it is truly trivial to share your project with a colleague, and this project is guaranteed to work for them!
And that's it! We hope that DrWatson will take some stress out of the absurdly stressfull scientific life!